...you know in SSIS when you have to create a parameter based OLE DB command (UPDATE tablename SET column1 = ?, column2 = ?, etc) well an easy way of getting the SQL statement together without the pain of typing those ? in yourself is this.
Right click on the table in SQL Management Studio and create a script to update the table you’re looking to update. Then do a Ctrl H (search and replace) which then gives you the option to replace based on a wildcard search. Search for “= <*>” and replace with “= ?” and voila one update script ready for pasting into the OLE DB command.
Mind you it doesn’t help when you then have almost 100 columns to map out :(
Wednesday, August 30, 2006
Thursday, August 03, 2006
Simple SSIS Logging - Part 1, The Load ID
Logging in SSIS gives you plenty of options. You have the built in event handling as well as the purpose built logging options. How this is used tends to be pretty different dependent on what project you’re working on and in the majority of cases you’ll find yourself implementing something very similar every time, then you’ll have to implement something very similar into every package on every project. This is time consuming and a pain and you can lose out on a lot of information that to be honest you will need later on for administration.
Let me break it down into a few simple key elements that I believe are important in BI based SSIS projects. Firstly you need to be able to capture the start and end time of a particular process. Secondly, absolute traceability of the data from the source system interfaces through to the warehouse storage itself. Finally, organising the output from any logging into a known structure for later analysis.
The concept of a load ID is fairly familiar to anyone moving data out of a source into a staging database, or if you’re skipping the middle man, straight into a warehouse. The load ID can be a unique indicator based on the specific process execution that extracted the data or identifies a number of loads to different tables. In the second case the source dataset itself becomes part of the identifier.
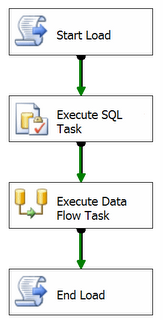
Typically the start load process will populate a known table in a logging environment somewhere and return to the package a Load ID. On a recent project this was built in to its own component that had properties such as the connection. The returned Load ID will get tagged onto each of the records that are written in the Data Flow Task. Using this information, along with the data source or file, you have full end to end coverage of where a record came from and where it has ended up in, for the purposes of this say, the staging database.
Obviously there’s a little more to this than just putting a script at the top and bottom of the control flow but not much more. The structure of the table that both provides the Load ID and logs the start time, end time and also the status of a particular load is pretty simple.
 click on image to enlarge
click on image to enlarge
There’s a bunch of other information you can attach to this table such as the package name, source server, pretty much anything you like. The important thing is capturing the core data and the real power comes from the reporting available from such a narrow dataset. Add the environment type and you can make comparisons between development, test and production performance. Add in a process identifier and you can see if one of your processes for transforming BI data is affecting a daily load task performed on one of your transactional systems.
Although this provides a very simple mechanism for logging and tracking SSIS packages, that’s all it does. For even more detailed information and to track problem areas within a package, a whole new level of logging is required. That I’ll go into in another post. I am of the view that structuring logging in this fashion not only provides benefits for administration after us consultant types have cleared off site, but also speeds up implementation when you have a few simple SSIS components and a single logging database to deploy. All this and able to apply the K.I.S.S. * rule to the process.
* Keep It Simple Stupid
Let me break it down into a few simple key elements that I believe are important in BI based SSIS projects. Firstly you need to be able to capture the start and end time of a particular process. Secondly, absolute traceability of the data from the source system interfaces through to the warehouse storage itself. Finally, organising the output from any logging into a known structure for later analysis.
The concept of a load ID is fairly familiar to anyone moving data out of a source into a staging database, or if you’re skipping the middle man, straight into a warehouse. The load ID can be a unique indicator based on the specific process execution that extracted the data or identifies a number of loads to different tables. In the second case the source dataset itself becomes part of the identifier.
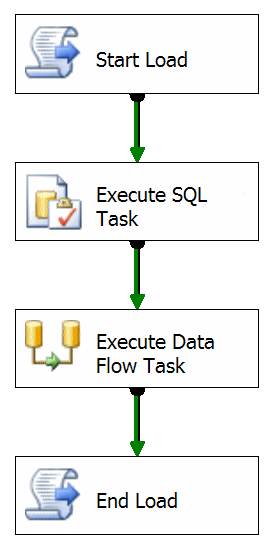
Typically the start load process will populate a known table in a logging environment somewhere and return to the package a Load ID. On a recent project this was built in to its own component that had properties such as the connection. The returned Load ID will get tagged onto each of the records that are written in the Data Flow Task. Using this information, along with the data source or file, you have full end to end coverage of where a record came from and where it has ended up in, for the purposes of this say, the staging database.
Obviously there’s a little more to this than just putting a script at the top and bottom of the control flow but not much more. The structure of the table that both provides the Load ID and logs the start time, end time and also the status of a particular load is pretty simple.
click on image to enlargeThere’s a bunch of other information you can attach to this table such as the package name, source server, pretty much anything you like. The important thing is capturing the core data and the real power comes from the reporting available from such a narrow dataset. Add the environment type and you can make comparisons between development, test and production performance. Add in a process identifier and you can see if one of your processes for transforming BI data is affecting a daily load task performed on one of your transactional systems.
Although this provides a very simple mechanism for logging and tracking SSIS packages, that’s all it does. For even more detailed information and to track problem areas within a package, a whole new level of logging is required. That I’ll go into in another post. I am of the view that structuring logging in this fashion not only provides benefits for administration after us consultant types have cleared off site, but also speeds up implementation when you have a few simple SSIS components and a single logging database to deploy. All this and able to apply the K.I.S.S. * rule to the process.
* Keep It Simple Stupid
Wednesday, August 02, 2006
Failure - Data Source Does Not Exist..!
One of the SSIS interfaces I have been working on a project pulls data from 10 identically structured databases. The task we had was to pull data for a particular day, supplied via a parent variable, and place the data into a single file for import into the staging database of the BI infrastructure.
The problem was that if one of the data sources was down, the WAN connection playing up or there was any other problem that would cause one of the data sources to fail, the entire package would fail. We didn’t want this behaviour because the client wanted as much data as possible rather than a complete failure.
For starters the OLEDB source wasn’t going to help us in this situation so we had to go for a scripted data source and changing the Acquire Connection code with a simple Try-Catch statement. This worked well and does the trick. We can run the entire package without any problems building up the connection string as variables that are passed into the script and connecting to the required single data-source. But then another requirement popped up.
How do I know when a data-source has failed, I don’t want the package to fail but a warning would be nice and enable us to capture the event in our logging mechanism. Enter the FireWarning method. This little diamond, along with its cousins FireError, FireInformation and FireProgress allows you to place custom entries into the SSIS logging.
I have an example package built on Adventure Works if anyone wants it and, although quite simple, I have come across a number of instances where connecting to multiple data sources (including flat file connections) where this behaviour is needed.
The problem was that if one of the data sources was down, the WAN connection playing up or there was any other problem that would cause one of the data sources to fail, the entire package would fail. We didn’t want this behaviour because the client wanted as much data as possible rather than a complete failure.
For starters the OLEDB source wasn’t going to help us in this situation so we had to go for a scripted data source and changing the Acquire Connection code with a simple Try-Catch statement. This worked well and does the trick. We can run the entire package without any problems building up the connection string as variables that are passed into the script and connecting to the required single data-source. But then another requirement popped up.
How do I know when a data-source has failed, I don’t want the package to fail but a warning would be nice and enable us to capture the event in our logging mechanism. Enter the FireWarning method. This little diamond, along with its cousins FireError, FireInformation and FireProgress allows you to place custom entries into the SSIS logging.
I have an example package built on Adventure Works if anyone wants it and, although quite simple, I have come across a number of instances where connecting to multiple data sources (including flat file connections) where this behaviour is needed.
Secret Source of Pleasure..
... or not so secret if you check out some of my other links over there -->
I am the proud owner of a launch day purchased Xbox 360 and in my spare time enjoy the odd thrash on there. My recommnedations at the moment are
Geomtery Wars - for a quick thrash on the machine.
Table Tennis - so simple yet so enjoyable.
Street Fighter II - coming to Xbox Live Arcade today, god I wasted so much of my time at college on that game..!
If anyone fancies a round or two on anything my gamertag is one1eg (that's a one in there).
See you online.
Steve
I am the proud owner of a launch day purchased Xbox 360 and in my spare time enjoy the odd thrash on there. My recommnedations at the moment are
Geomtery Wars - for a quick thrash on the machine.
Table Tennis - so simple yet so enjoyable.
Street Fighter II - coming to Xbox Live Arcade today, god I wasted so much of my time at college on that game..!
If anyone fancies a round or two on anything my gamertag is one1eg (that's a one in there).
See you online.
Steve

Other Places to go...
In my first proper contribution to this years blogging (yeah, yeah, I know) I was going to give a quick overview of some of the blogs I regularly read and why.
First up is a Mark Hill (http://markhill.org/blog). I've known Mark for a number of years and worked with him for almost all that time. His blog is in his own words "a ramble through Microsoft BI technologies". Give the guy a little credit here, it's not a ramble but quite an insightful comment on Microsoft’s BI platform and essential viewing if you're looking for information on the problems you'll face implementing large scale SSIS and Analysis Services systems and especially if you're looking to put 64 bit servers within your architecture.
Next is Thiru Sutha's SQL Server 2005 BI blog (http://tsutha.blogspot.com/). Again someone I've know and worked with for a number of years has been working on the same projects as Mark Hill and significantly contributed to stabilising 64 bit SSIS. Definitely worth a viewing and contains some good example SSIS packages for your pleasure in addition to postings on known SSIS bugs.
Chris Webb (http://cwebbbi.spaces.live.com/) is a pretty well known individual in the world of Microsoft business intelligence and is your first port of call if you need to know anything about using MDX in the field. His collaboration in the latest version of MDX Solutions (along with George Spofford amongst others) gives the book a lot more weight and makes it an excellent guide to anyone looking to enhance their MDX knowledge.
Off the BI band wagon slightly here The Joy of Code (http://www.thejoyofcode.com/) is a collaborative blog that includes Josh Twist, a colleague I’ve worked with recently on a SQL Server 2005 BI architecture implementation. Josh is .Net developer by trade but was huge benefit to the projects custom SSIS component development. A number of the SSIS components he worked on are available there with example code for download, some of which I’ll discuss in further detail later along with some recommended applications.
Finally another SSIS orientated blog from Jamie Thomson (http://blogs.conchango.com/jamiethomson). I have, lets say, borrowed plenty of SSIS code from this site recently and his postings on things like what you could do in DTS but aren’t as obvious in SSIS are very useful for anyone making that transition.
Well that’s it for now hopefully you’ll find these sites as useful as I have.
Steve
Confession of a Freelance Dolphin Trainer...
Forgive me Blogger for I have sinned.
I've slacked in the blogging world in recent months so I thought I would get my ass into gear and whilst my time isn't complete monopolised with the daily grind I thought I would contribute to the amount of information currently in existence.
The next few post will be general updates on what is happening in my world be it work related or not.....
Steve
I've slacked in the blogging world in recent months so I thought I would get my ass into gear and whilst my time isn't complete monopolised with the daily grind I thought I would contribute to the amount of information currently in existence.
The next few post will be general updates on what is happening in my world be it work related or not.....
Steve
Subscribe to:
Comments (Atom)


