Let me break it down into a few simple key elements that I believe are important in BI based SSIS projects. Firstly you need to be able to capture the start and end time of a particular process. Secondly, absolute traceability of the data from the source system interfaces through to the warehouse storage itself. Finally, organising the output from any logging into a known structure for later analysis.
The concept of a load ID is fairly familiar to anyone moving data out of a source into a staging database, or if you’re skipping the middle man, straight into a warehouse. The load ID can be a unique indicator based on the specific process execution that extracted the data or identifies a number of loads to different tables. In the second case the source dataset itself becomes part of the identifier.
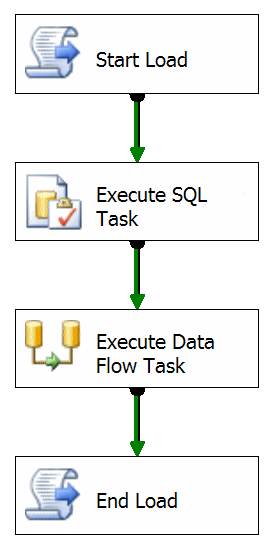
Typically the start load process will populate a known table in a logging environment somewhere and return to the package a Load ID. On a recent project this was built in to its own component that had properties such as the connection. The returned Load ID will get tagged onto each of the records that are written in the Data Flow Task. Using this information, along with the data source or file, you have full end to end coverage of where a record came from and where it has ended up in, for the purposes of this say, the staging database.
Obviously there’s a little more to this than just putting a script at the top and bottom of the control flow but not much more. The structure of the table that both provides the Load ID and logs the start time, end time and also the status of a particular load is pretty simple.
 click on image to enlarge
click on image to enlargeThere’s a bunch of other information you can attach to this table such as the package name, source server, pretty much anything you like. The important thing is capturing the core data and the real power comes from the reporting available from such a narrow dataset. Add the environment type and you can make comparisons between development, test and production performance. Add in a process identifier and you can see if one of your processes for transforming BI data is affecting a daily load task performed on one of your transactional systems.
Although this provides a very simple mechanism for logging and tracking SSIS packages, that’s all it does. For even more detailed information and to track problem areas within a package, a whole new level of logging is required. That I’ll go into in another post. I am of the view that structuring logging in this fashion not only provides benefits for administration after us consultant types have cleared off site, but also speeds up implementation when you have a few simple SSIS components and a single logging database to deploy. All this and able to apply the K.I.S.S. * rule to the process.
* Keep It Simple Stupid



No comments:
Post a Comment